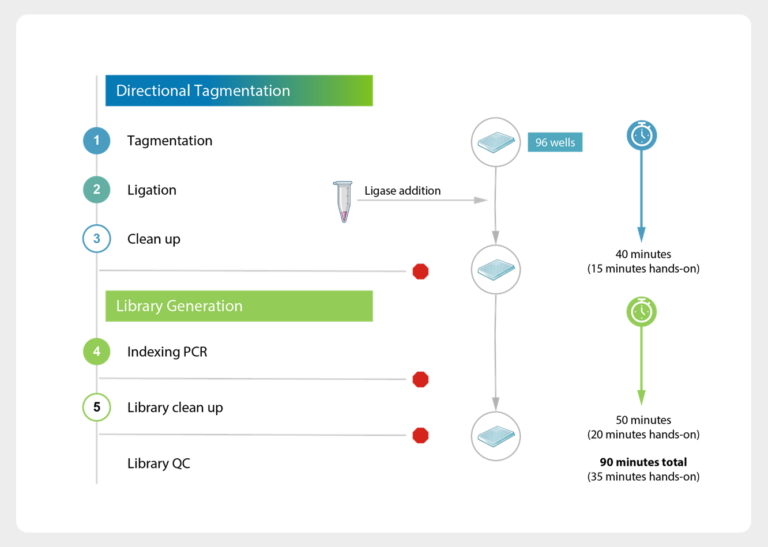
Proteomics in Transition: From Discovery to Diagnostic Relevance Whitepaper


Dr. Ebru Boslem
ANZ Market Manager - Research Genomics
ANZ Market Manager - Research Genomics

ANZ Market Manager - Research Genomics


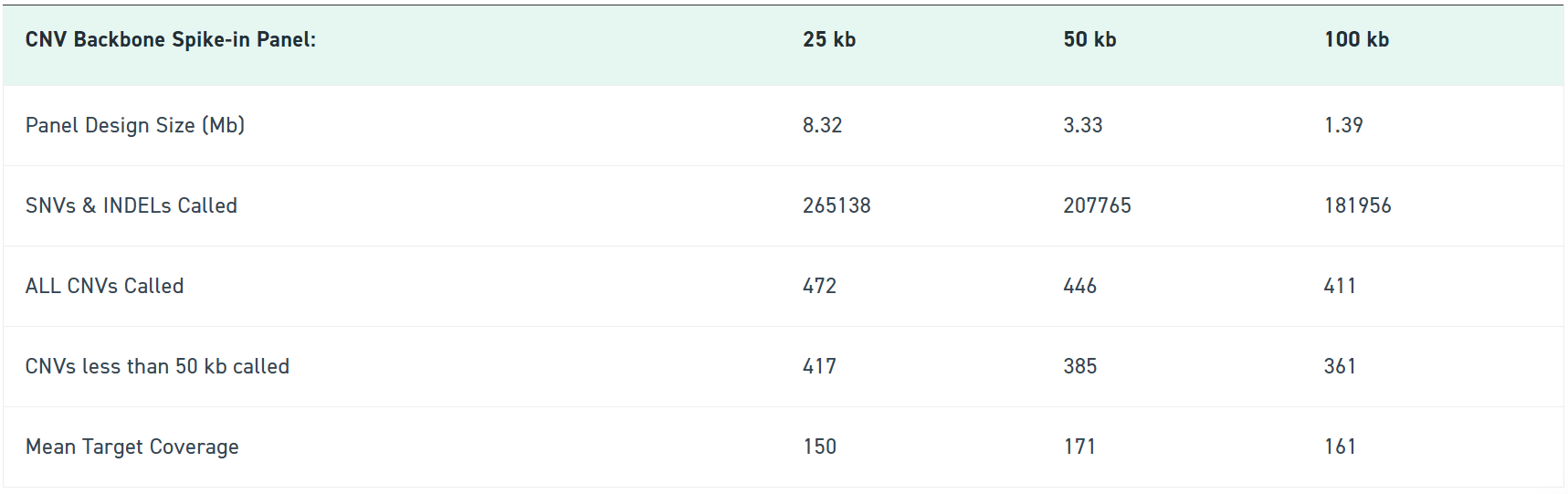
Table 1. Example data of Twist CNV Backbone Spike-in Panels. A highly characterized sample set known to contain CNVs (1) and a baseline set of 12 healthy individuals were sequenced with 2×150 reads on an Illumina NovaSeq 6000. The average number of SNVs, INDELs, and CNVs called and sequencing depth at each probe density was determined for each panel when spiked into Twist Exome 2.0 plus Comprehensive Spike-in. CNV calling was performed with a commercially available software solution (2)
(1) Coriell Institute’s CNVPANEL01 – Human CNV Reference Panel.
(2) eVai Platform (secondary workflow), enGenome Software.

Clinical Genomics Manager - ANZ
& Country Manager - NZ
Raise confidence in variant detection with superior target enrichment solutions
Precision, uniformity, and flexibility for results you can trust

Synthetic RNA and DNA standards for assay development
Identify more hits and streamline screening with Twist's precise Variant Libraries


Country Manager - NZ

Country Manager - NZ

Business Development Manager
Raise confidence in variant detection with superior target enrichment solutions
Precision, uniformity, and flexibility for results you can trust
Synthetic RNA and DNA standards for assay development
Identify more hits and streamline screening with Twist's precise Variant Libraries
ANZ Market Manager - Research Genomics



Business Development Manager
ANZ Market Manager - Research Genomics