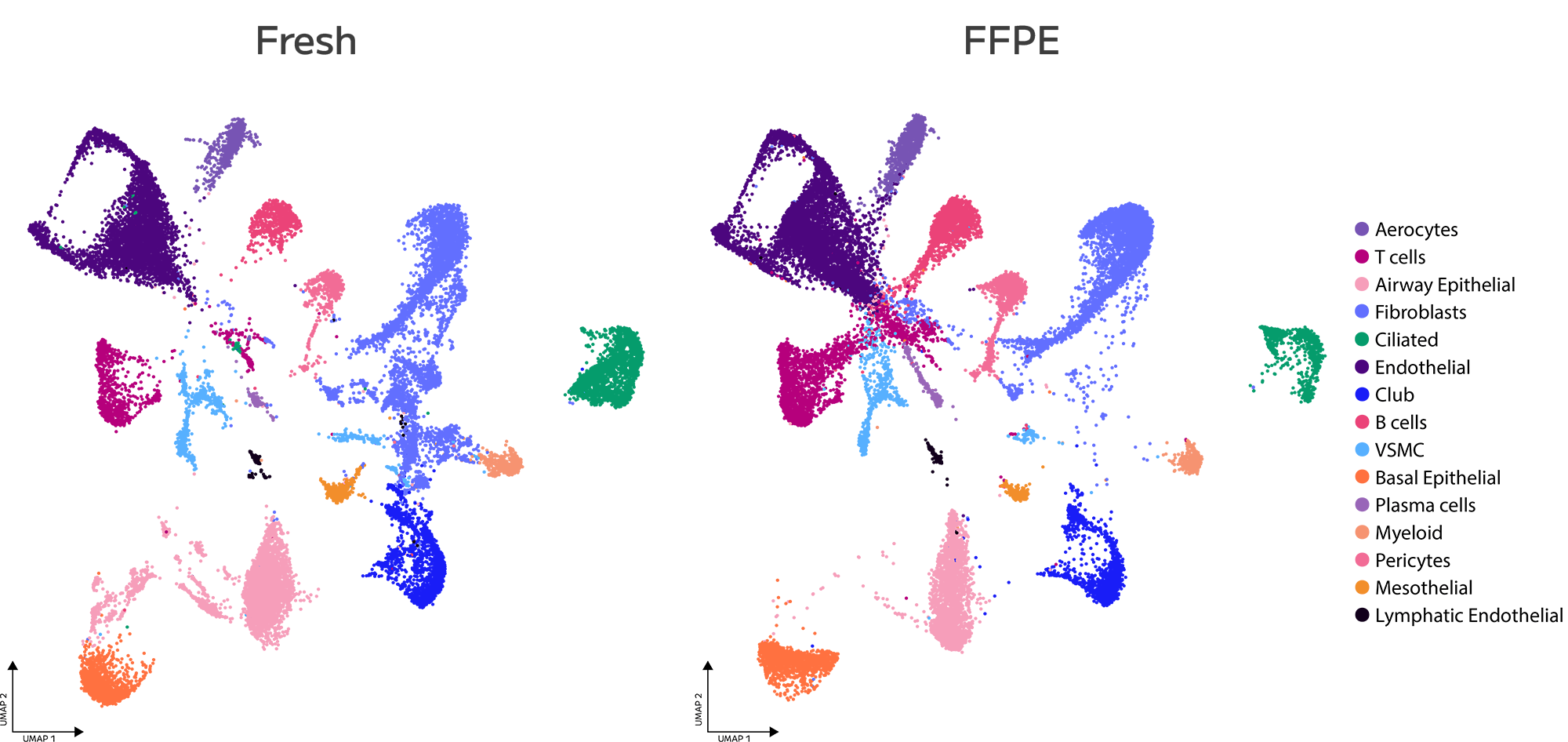Decode Multi-Omics Discovery Day
/in Seminar/by Harshita SharmaDecode Multi-Omics Discovery Day
FREE HALF-DAY SEMINAR · ANZ · 2026
Partner. Discover. Solve.
From single-cell and spatial whole transcriptomics to ultra-sensitive proteomics — spend an afternoon with the Decode Science team and see how an integrated multi-omics workflow can refine your next discovery. Four leading research institutes. Limited seats.
CLICK THE DATE BELOW TO REGISTER
Tuesday 4th August - Peter Doherty Institute
On Site: Ebru & Julia
Tuesday 12th August - Baker Heart & Diabetes Institute
On Site: Ebru & Julia
Wednesday 30th September - Florey Institute
On Site: Ebru & Julia
Early October
On Site: Ebru & Julia
Partner
Decode Science is the authorised ANZ distributor for the world’s leading omics platforms — with local applications scientists beside you at every step.
Discover
See single-cell, spatial and proteomic technologies in action — alongside real customer data from institutes working at the frontier.
Solve
Leave with a clear path to your next experiment — and the chance to win a discounted pilot project to put it into motion.
THE TECHNOLOGIES
The complete multi-omics picture, in one afternoon
Two complementary halves — single-cell & spatial whole transcriptomics, then the expressed and soluble proteome — built from the platforms Decode partners with across Australia and New Zealand.
1
Transcriptomics — single-cell & spatial, at the highest resolution
MGI — Single Cell
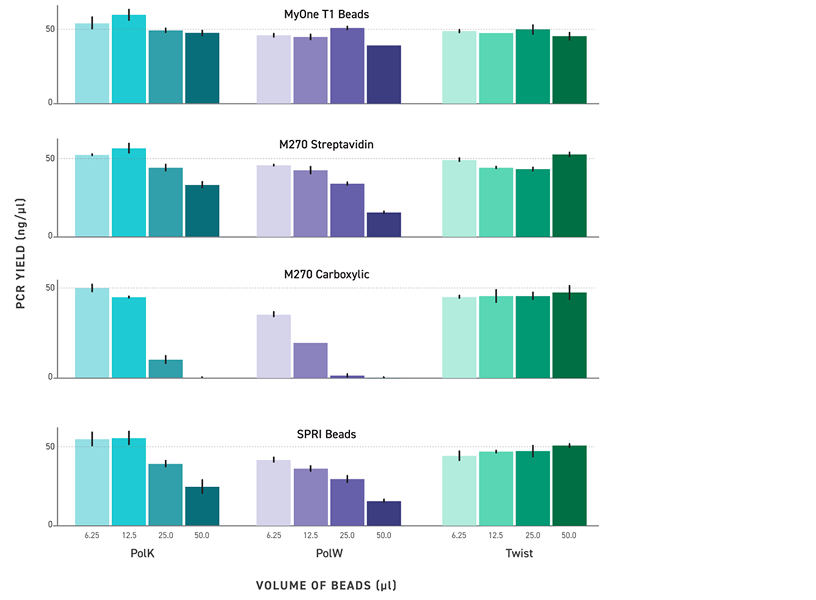
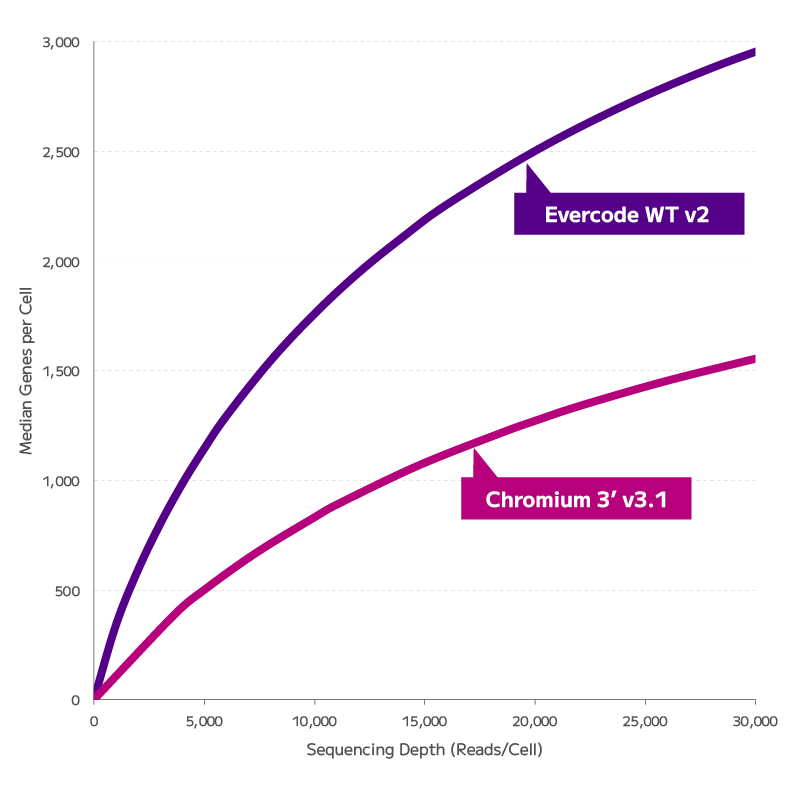
Multi-omics for your small-scale single-cell projects, on MGI’s DNBSEQ platform.
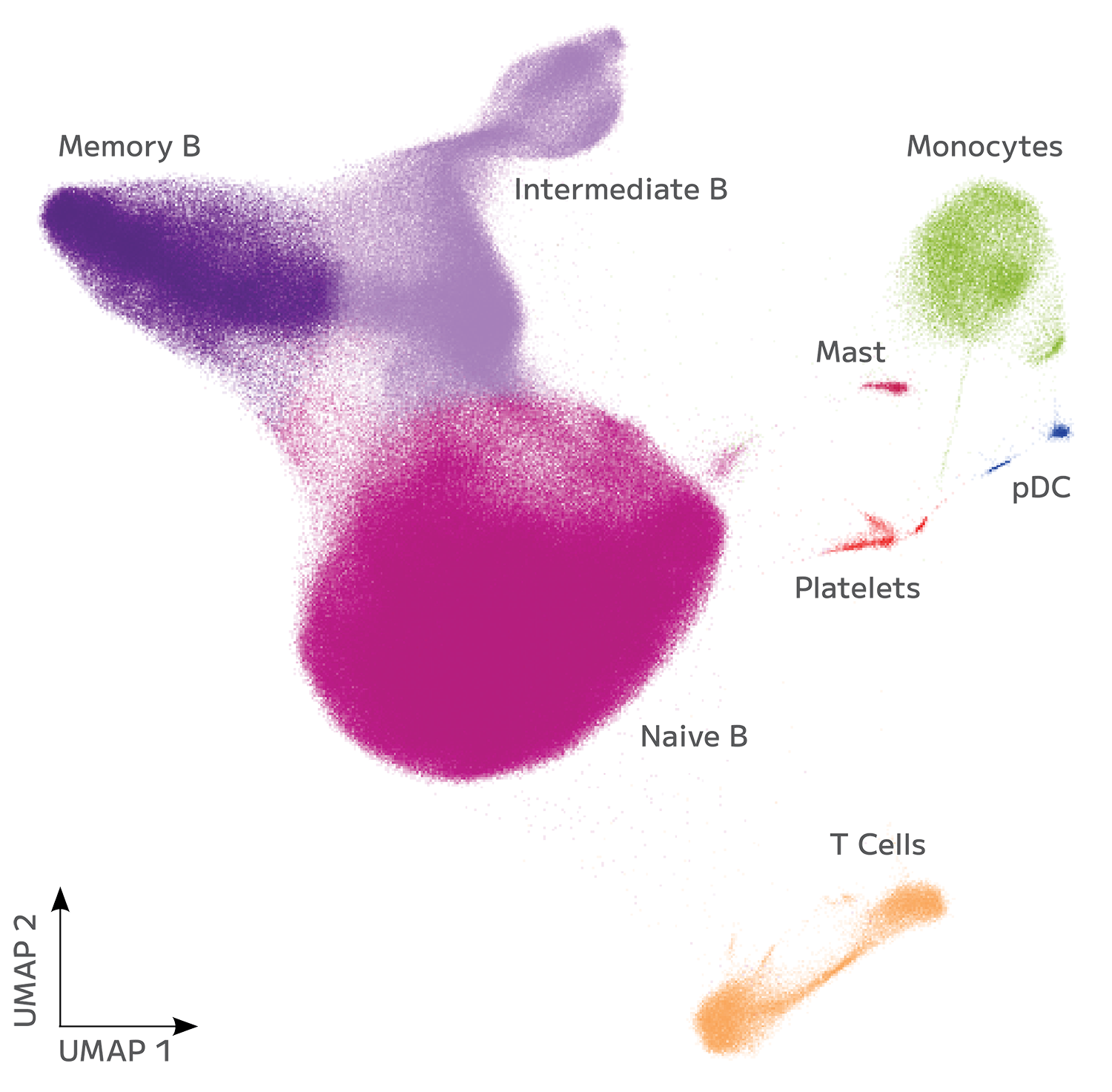
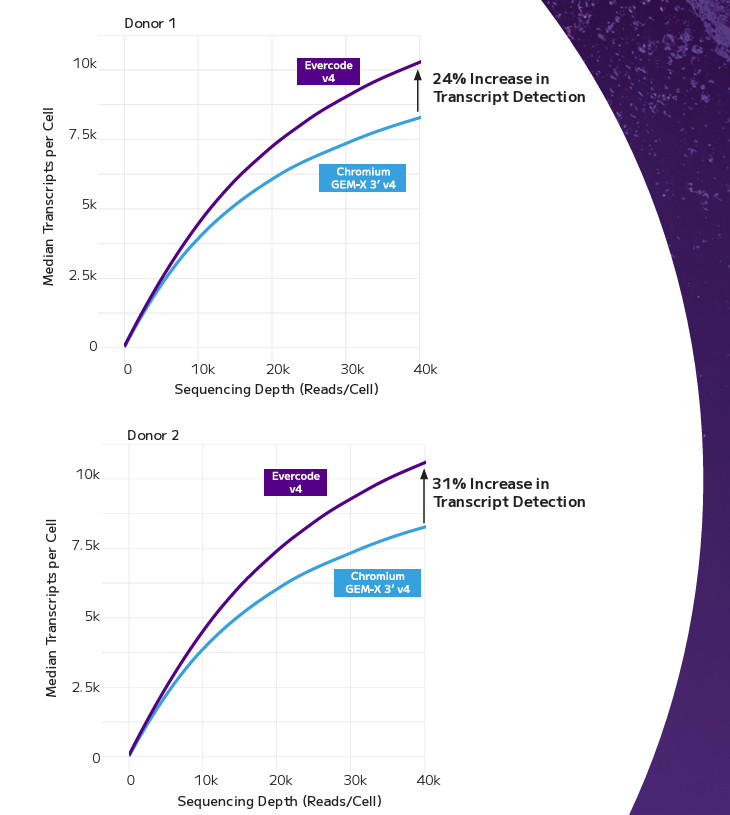
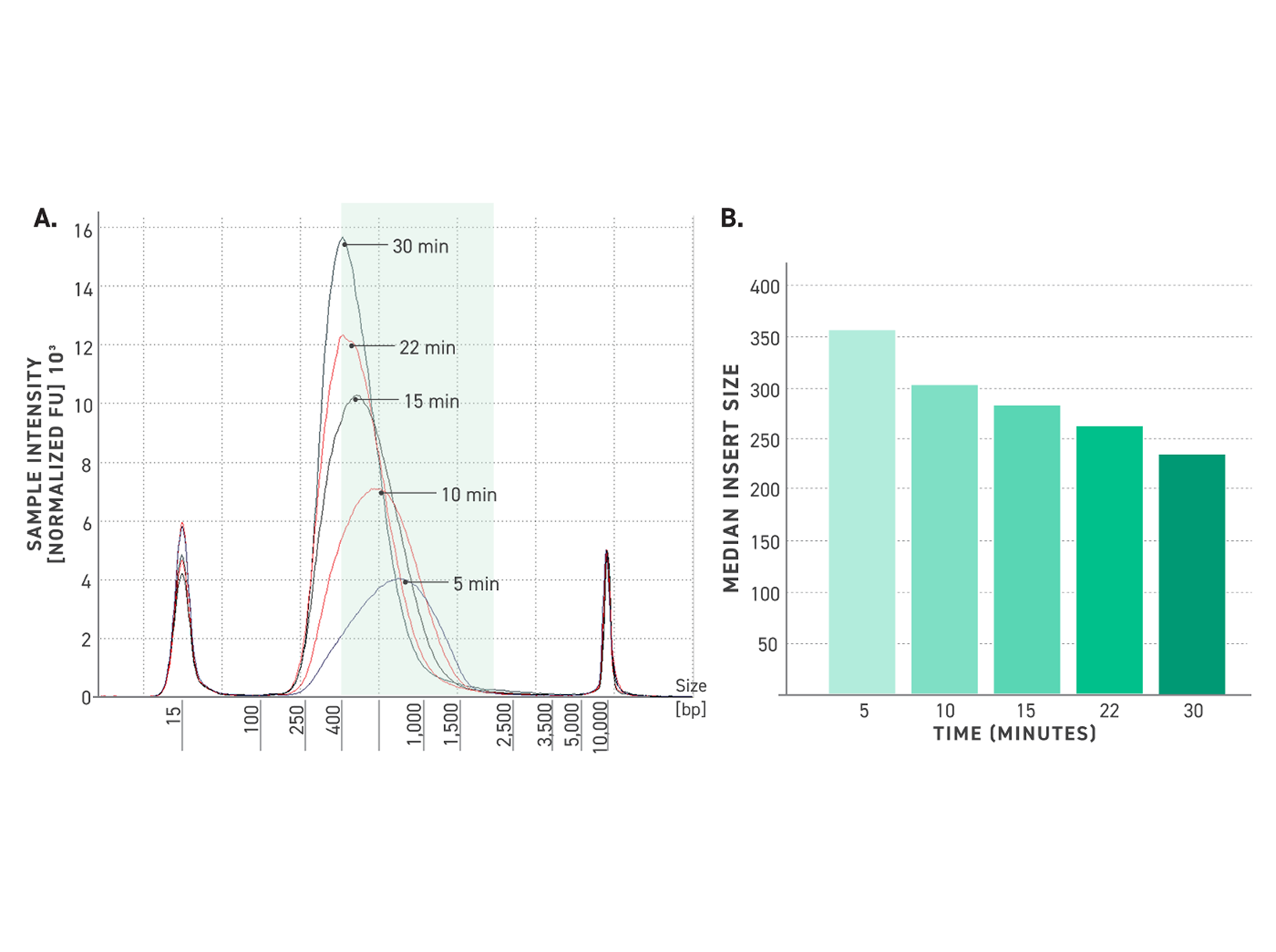
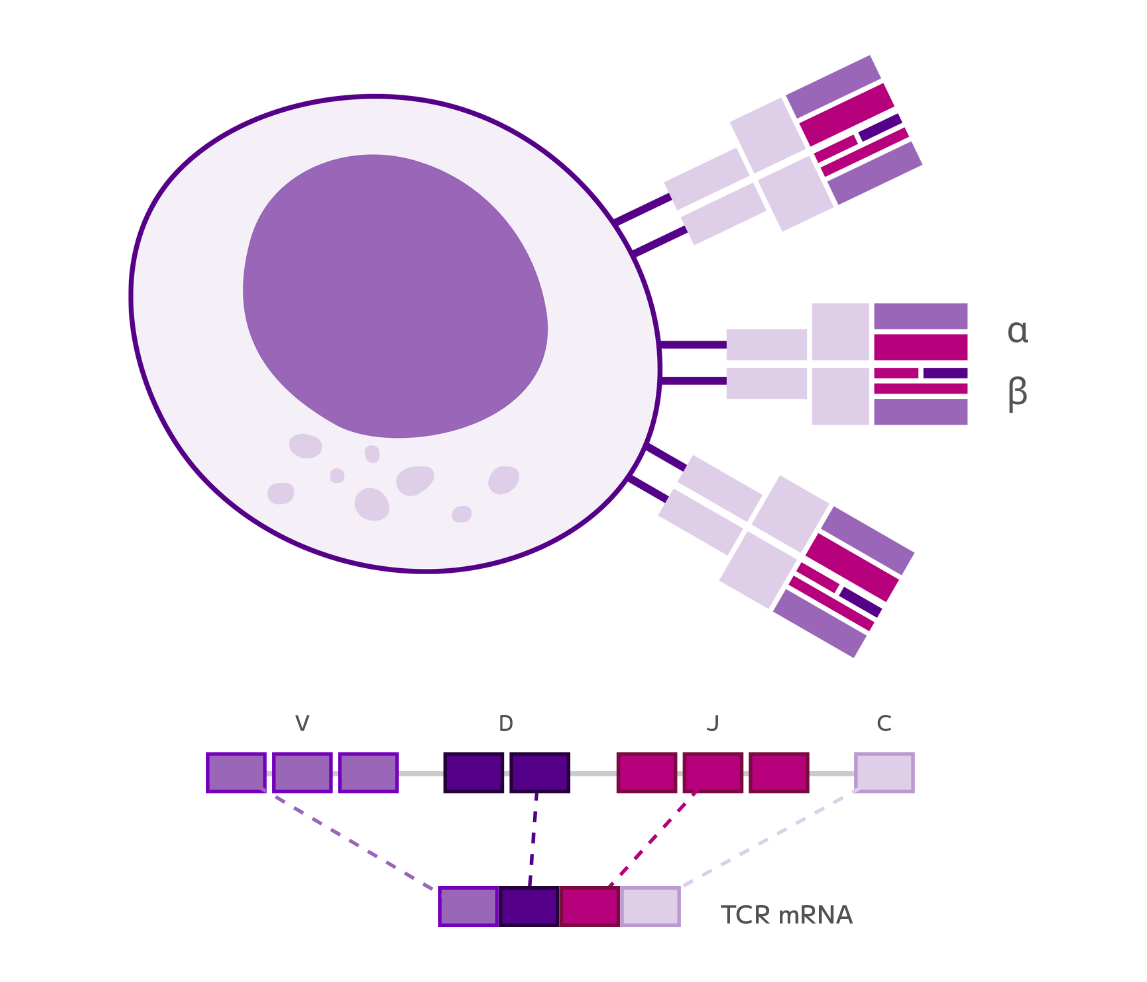
Parse Biosciences
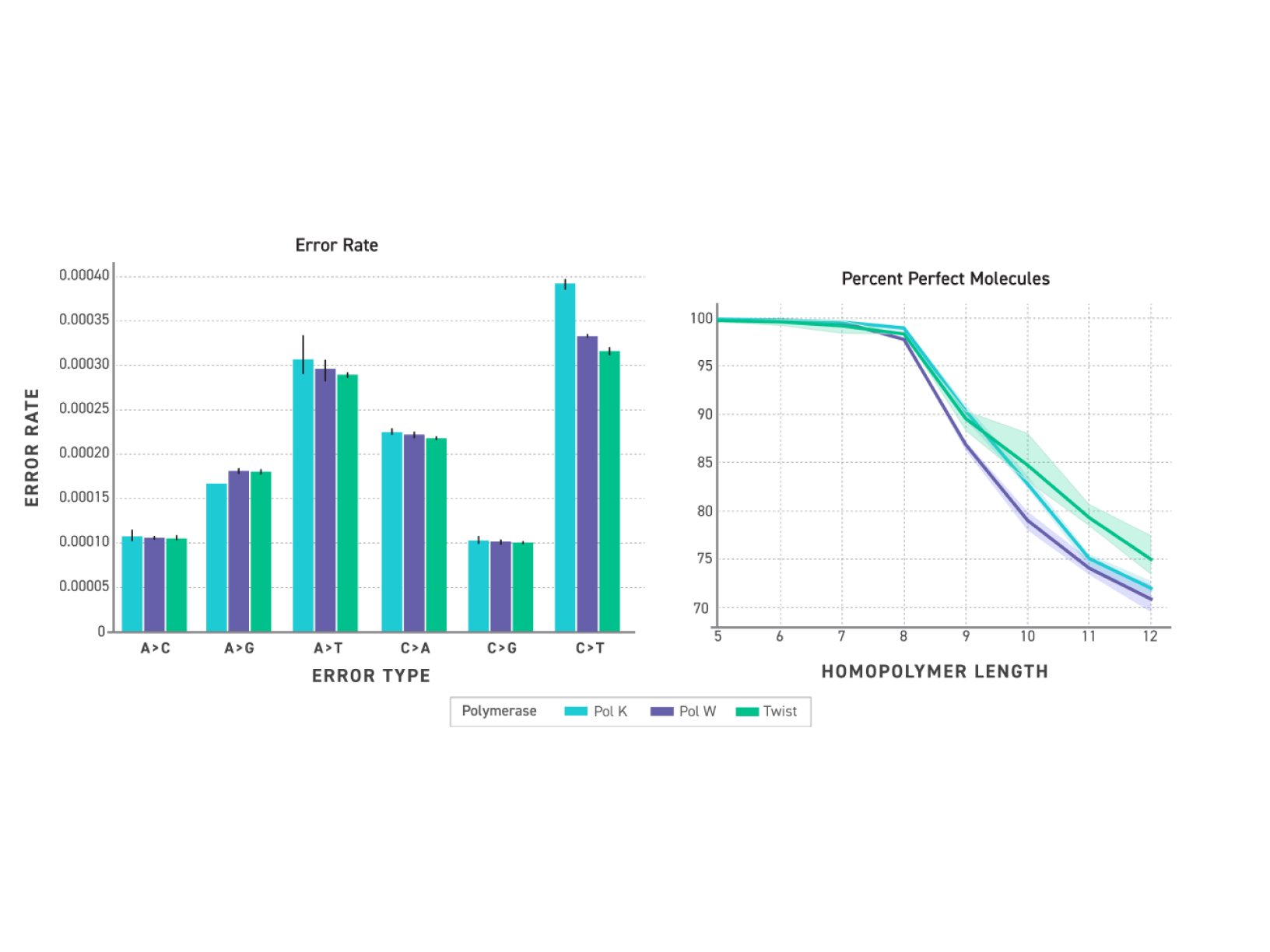
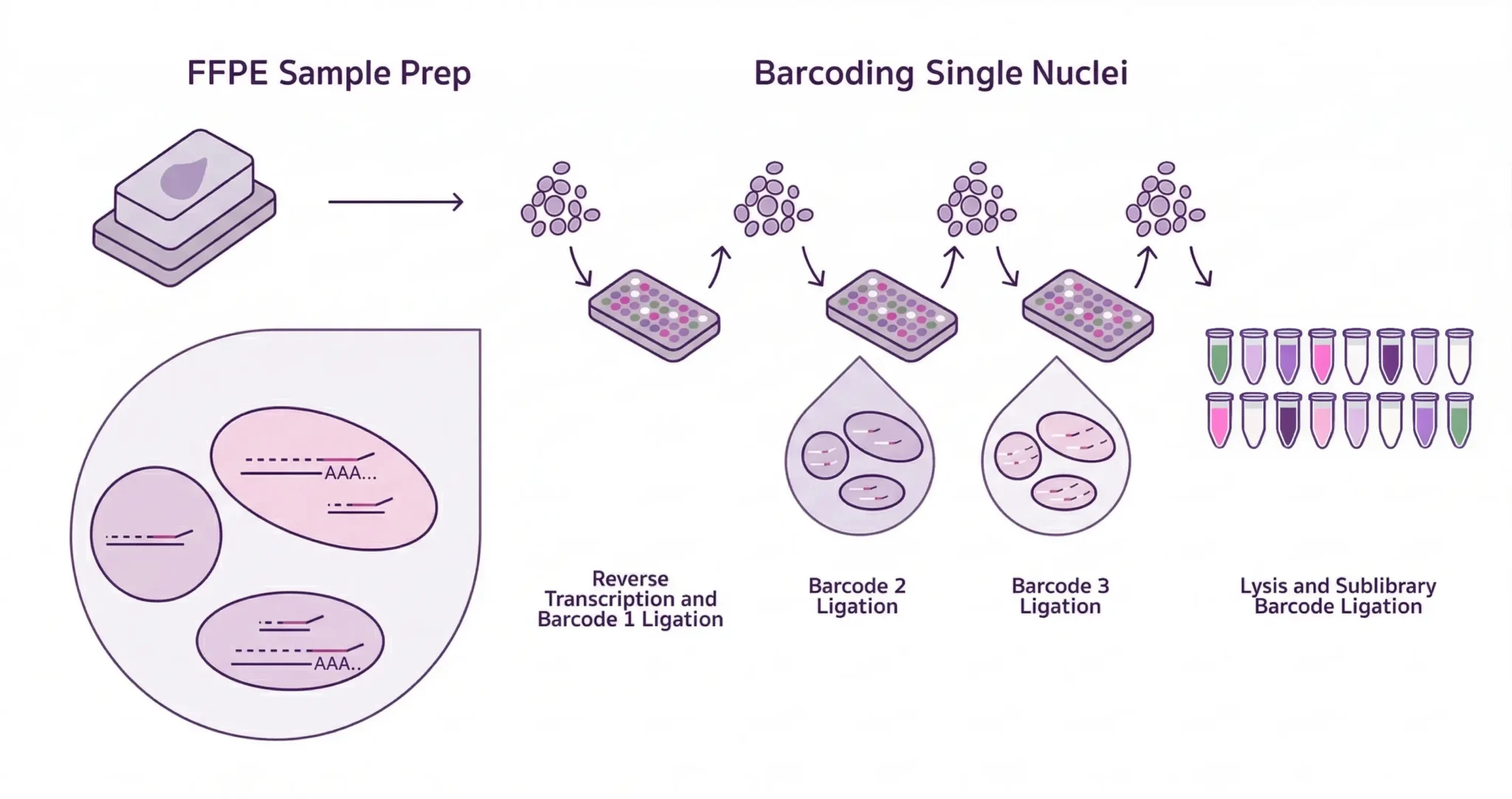
High-throughput single-cell whole transcriptomics and TCR/BCR discovery, powered by fixation and combinatorial barcoding.
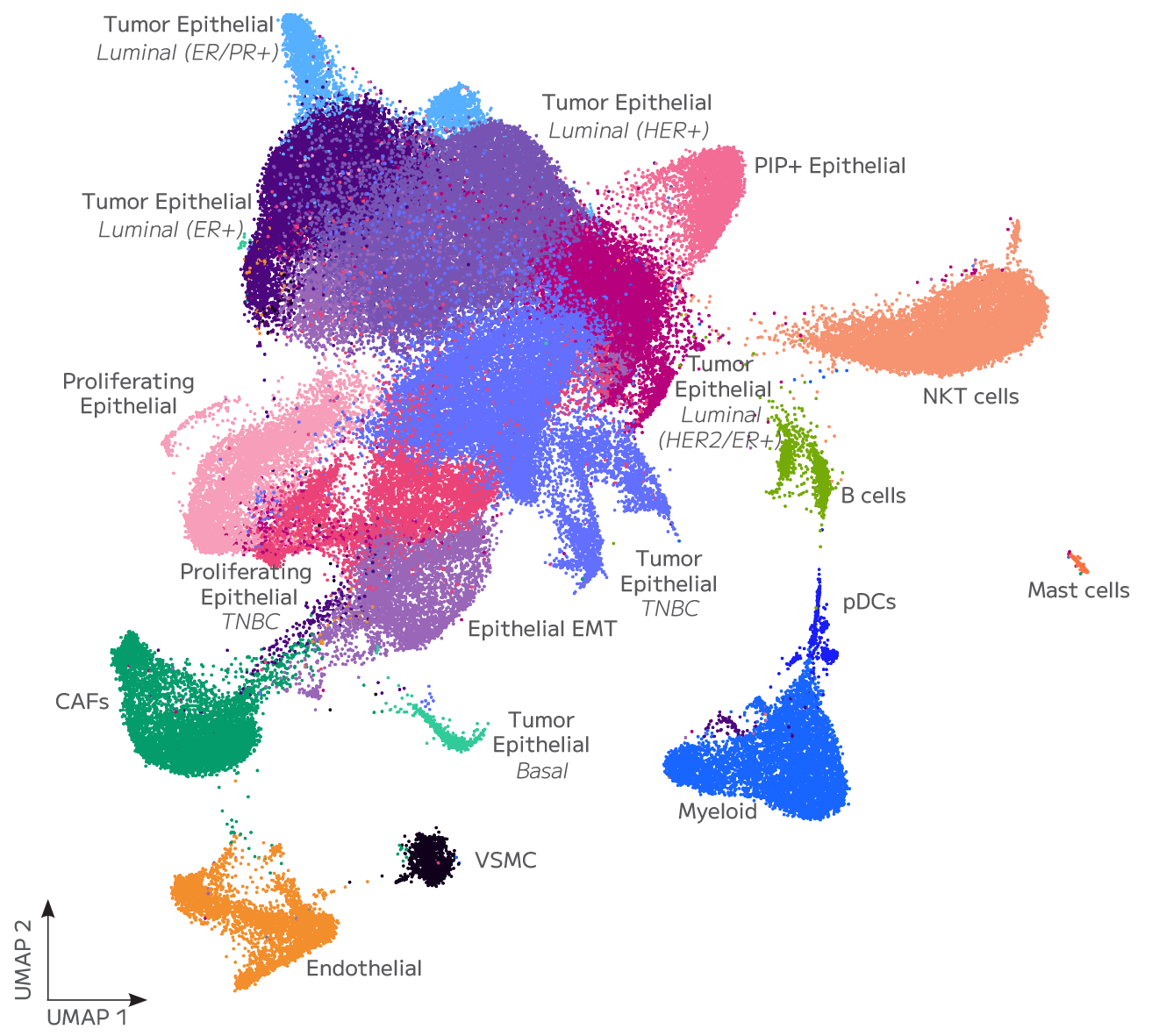
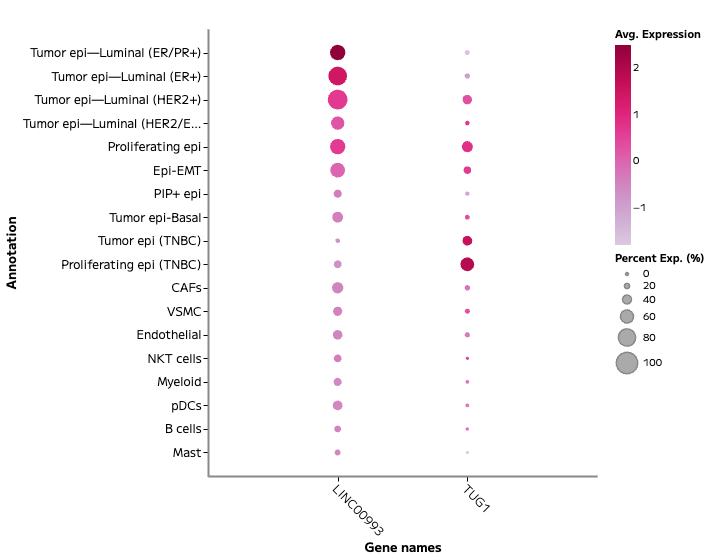
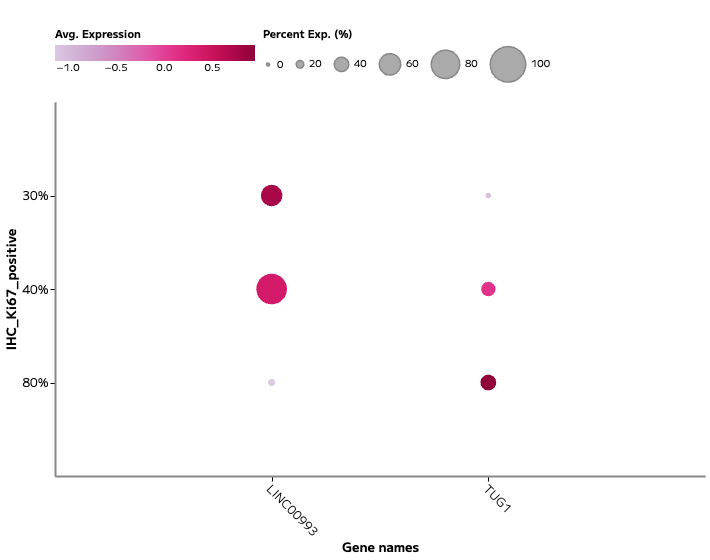
STOmics — Stereo-seq
Spatial whole-transcriptomic and multi-omic capture, at single-cell resolution across a centimetre-scale field of view.
Atrandi Biosciences
Scalable single-cell multi-omics using semi-permeable capsule technology for ultra-high-throughput workflows.
2
Protein & biomarkers — completing the picture
Akoya Biosciences
Spatial proteomics — map the expressed proteome in tissue context, alongside your transcriptomic data.
Quanterix — Simoa
Ultra-sensitive detection of circulating biomarkers in the soluble proteome.
THE AGENDA
A half-day, end to end
Same program at every venue. Presented by the Decode Science team, with guest customer data from leading institutes.
2 min
Welcome — Partner. Discover. Solve.
Refine your discoveries with Decode Multi-Omics solutions.
Ebru Boslem · Decode Science
PART 1 · TRANSCRIPTOMICS
Single-cell & spatial whole transcriptomics — biology at the highest resolution
10 min
MGI SINGLE CELL
Multi-omics for your small-scale single-cell projects
Ebru Boslem · Decode Science
15 min
PARSE BIOSCIENCES
High-throughput single-cell whole transcriptomics & TCR/BCR discovery
Powered by fixation and combinatorial barcoding.
Ebru Boslem · Decode Science
15 min
CUSTOMER DATA
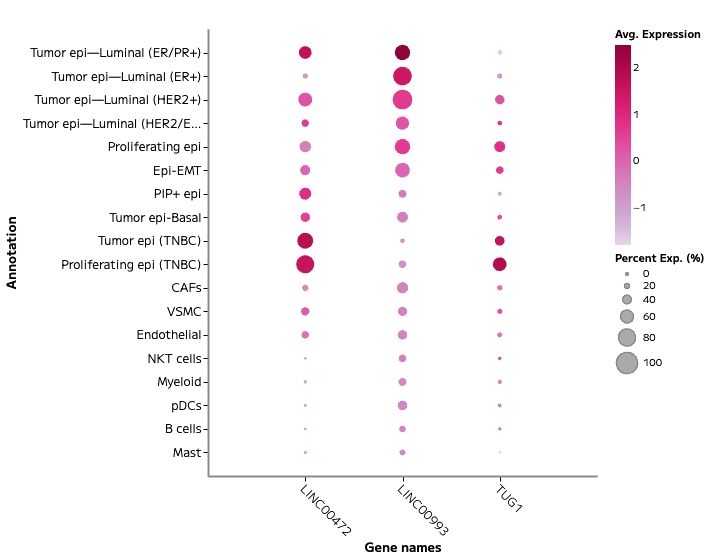
Parse TCR & BCR profiling of human malaria-infected spleen
Burnett Institute · speaker TBC
15 min
MGI STOMICS
Spatial whole-transcriptomic & multi-omic capture, at single-cell resolution
Ebru Boslem · Decode Science
15 min
CUSTOMER DATA
STOmics manuscript — human spleen profiling
Peter Doherty Institute · speaker TBC
30 min
Morning tea & networking
LUNE croissants and bubble tea.
PART 2 · PROTEIN & BIOMARKERS
Complete the picture with the expressed and soluble proteome
15 min
AKOYA BIOSCIENCES
Spatial proteomics
Julia Young · Decode Science
15 min
CUSTOMER DATA
Customer Spotlight
ONJCRI
5 min
QUANTERIX
Ultra-sensitive circulating biomarker detection
Julia Young · Decode Science
10 min
POLLS & GIVEAWAY
Spin the wheel — discounted pilot project & prizes
Interactive poll and giveaway to close the day.
Julia Young · Decode Science